With any modern development project, I feel, you need to have good DevOps if you want a chance to be successful. Luckily, Microsoft has done a lot of investing into Visual Studio Online so that it is a one stop shot for development teams. Among these tools is a cutting edge Build and Release pipeline system.
In this post, I wanted to walk through my approach to handling a CI/CD pipeline with VSTS and containerized builds being deployed using App Services.
By the end you will end up with two builds: One which performs your typical CI Dev build that runs after each remote push, this will have a linked Release that deploys the created image to a Dev App Service. Similarly, you will have a Release Build that is triggered when a tag is pushed to the remote. It builds the image and tags it with the value from the Git tag. Finally, we will create a Staging Deployment where by users manually create releases and deploy specific versions to higher environments.
This is not a short post so, let’s get started.
Creating the CI Build
One of the most important builds for any development team is the CI or Continuous Integration builds. For this build, whenever we merge to our develop branch we want to build an image and, if valid, deploy it to our Azure Container Registry (ACR).
For starters, we need a Dockerfile that can create the image we will deploy to ACR. Here is the Dockerfile I used:
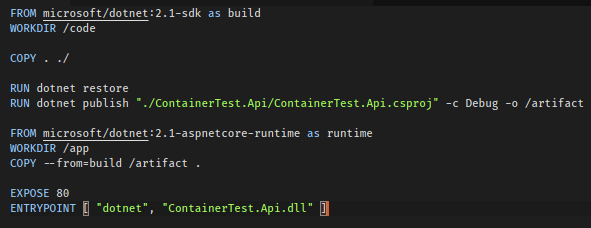
This is what is known as a multi-stage build where we separate the build and runtime components of our container, this reduces the size of the final container as SDKs can be rather large and are not needed to actually run code.
Here are the steps:
- Download version 2.1 of the dotonet core SDK and refer to this stage as build
- Set the working directory on the image to /code
- Copy everything from the current directory into /code (our current working directory)
- Run the dotnet restore command to restore our Nuget packages
- Run the dotnet publish to build our application in Debug (it is a Dev build) and send the contents to /artifact
- Download version 2.1 of the aspnetcore-runtime and name this stage runtime
- Create your working directory /app
- Copy all contents from /artifact from the build stage to the current working directory (/app)
- Expose port 80 on spawned containers
- Set the Entrypoint for the container as ContainerTest.Api.dll
We will create a derivative of this for the release build later on.
On VSTS, you will need to enter into the Builds and Releases section and click New +this will open the wizard to create a new pipeline.
First screen is selecting the source you want to download, we want to use develop since this is the branch our task and feature branches will ultimately come into. So this build will happen very frequently as an attempt to make sure changes dont break anything.
Next screen we pick our base template, Docker Container will be our selection. This will call our Dockerfile and expect to publish the image to a registry, we will use ACR for this, but you could use any Registry you so desired.
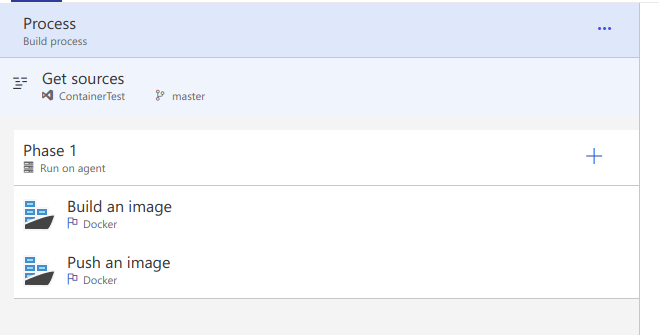
Important: You must make sure that the image(s) you build and the image(s) you publish are the same, or this process will fail.
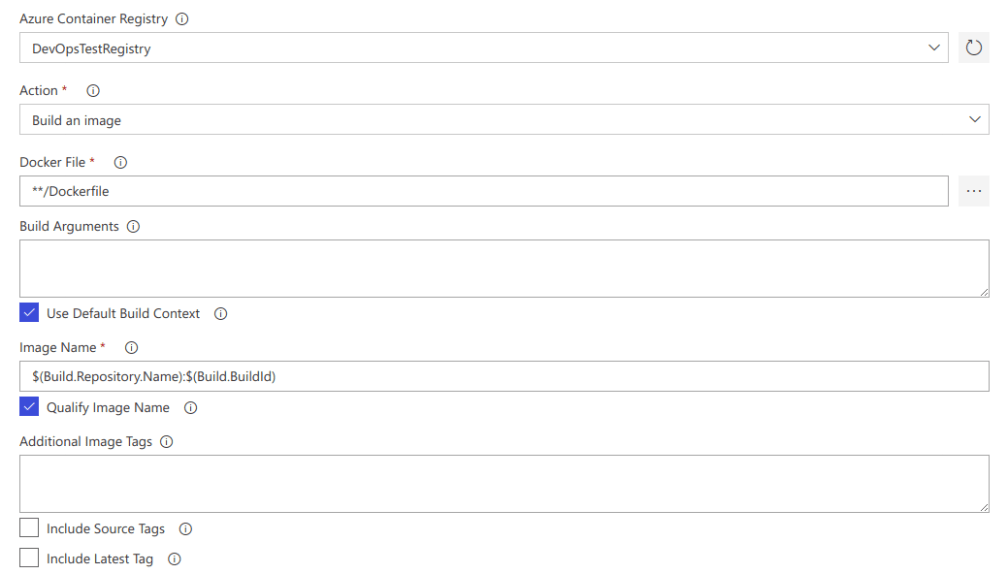
Let’s go through the fields here, all of them are duplicated in the Publish task as well:
- Azure Container Registry – because I indicated that this would be where my images are stored I was asked to select the registry. There is a field above this to select the Azure subscription, I have hidden it here for security
- Action – this is obvious, the values will differ between Building and Publishing for obvious reasons
- Dockerfile – again, obvious, we can leave the default here.
- Image Name – Ok, so this is the actual name and tag of the image you will create. In ACR the image maps to a Repository and each individual item in that repository will be a tag
- In this case we use the repository name as the repo name and the BuildId value as the tag. We can update the tag to be whatever we want
- Ex: $(Build.BuildNumber)-$(Build.SourceVersion)
- Additional Image Tags – new line delimited list if you want to create additional tags within the repo, or if your tag structure is long
- Include Source Tags – will create a tag for any Git tag that is pushed
- Include Latest – common practice in Docker, latest refers to the latest build for the image. You can also not include any tags and latest will get pushed
Again, it is critical that we duplicate the image name fields in the publish task so that it can find the image we just built.
Finally, we need to indicate that this is a build that is kicked off when the develop branch is pushed to. To do this, we edit our Build Pipeline and select the Trigger tab. Click to Enable Continuous Integration. Make sure you have develop specified. This will ensure the build is kicked off when develop is modified.
Releasing
Now, oddly enough even if you create a latest image and set your App Service to use the latest container it will not update when you push, because the App Service has to be told to update, and that is where the Release pipeline comes in.
First, hit Azure and create an App Service (Web App for Containers), when creating be sure to select Container (if you select Web App for Containers you wont have a choice).
Now, you will be asked to define a default image so, best to do this once one of your build from CI has completed. Be sure to test that it works after the provisioning process is complete.
Returning to VSTS, go to Releases. Release pipelines can do all the same things as Build pipelines but, their targeted purpose is to respond to a completed build or manually release code selected from completed builds.
When you select to Create a release pipeline you will be met with a side menu that requests selecting a template. For this case, we select Azure App Service Deployment.
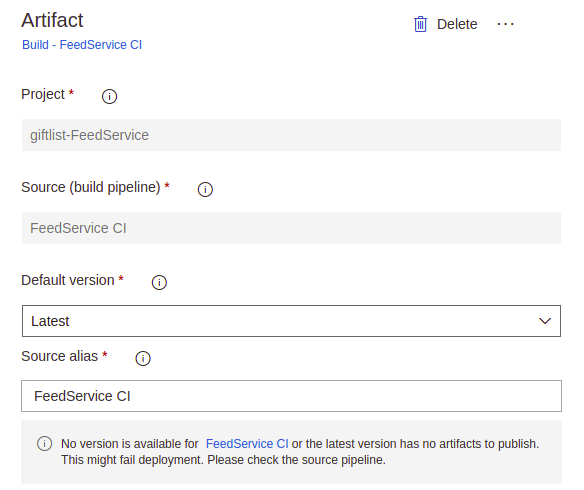
Our next step is to determine what will be released and that means selecting an Artifact. There are many options here but, for this step since we want this release to happen whenever the CI build finishes we select Build. When you do this, most of the fields will get filled in, the Source Version Alias can be whatever you want, its just the name of the incoming artifact.
After we select our artifact we need to tell the release what to do. For our case, this is going to be super simple: we are going to deploy the image built in the Build Phase to our Dev environment AppService. Click the Phase link beneath the Environment.
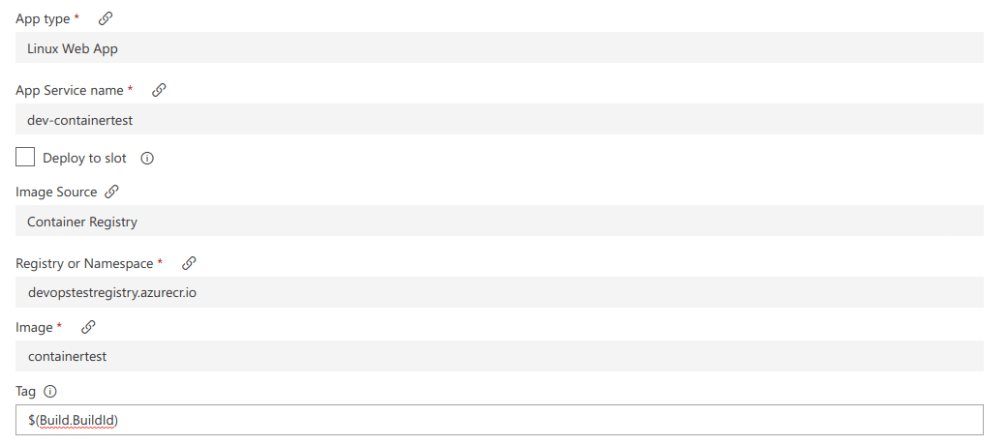
So, let’s go through these settings cause they are important to understand:
- App type: Must set this to Linux Web app because the images are all using Ubuntu
- App Service name: So, I have noticed that if you dont use the Web App for Containers that it doesnt seem selectable in the menu, hence I mentioned using that template above
- Image: The image you want to target, this is case sensitive
- Tag: the tag you are deploying. Some of the environment values are carried over from the build, one of them is the BuildId
The last thing we need to do is set up our Release trigger. We can trigger releases manually, which will be the case for UAT and Production and, to some extent, QA. But for Dev we want it to have the latest and greatest.
So, once you have this in place, its time to test our CI build. Make a change and push to develop.
The build should start up and, hopefully, finish successfully (use the Download log on the Build detail to debug failures). After it finishes, switch over to Releases. You should see the next build start up.
Once that finishes, refresh your AppService endpoint and, after a time, you should see the change. If you get Service Unavailable, it usually means that you attempted to specify with an image tag that does not exist. To confirm this, view the Container Settings for your App Service and, if Tag is blank (or any required fields) it means the deployment specified the wrong tag. You can further confirm this in the Log for the Release.
That completes our first goal, we have a CI build which deploys to our AppService, up next is QA.
Creating the Release Build
Ideally, I wanted this build to kick off whenever a version tag was pushed to the develop branch. From this, we can tag the generated image file with its version and very easily have a historical listing of the versions that can be used by App Services and via the Release pipeline.
Before going any further its important that we understand how we can automatically invoke a build from a tag push, since it is not immediately obvious.
When you create a tag it is created at the path /refs/tags/<tag name>. Most build engines are wired to look for branch changes using a similar path structure. Knowing this we can hijack this to launch our build when a tag is pushed.
Clone the CI build and go into Edit it, click Triggers. You will need to enable Continuous Integration, as you did for the CI build. But you wont use a branch this time (shown below)
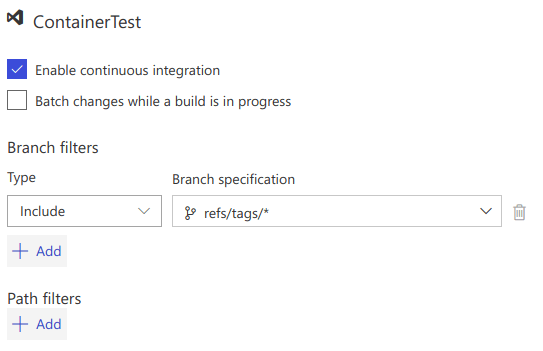
That is all there is to it. Now we just need to make some changes to our build process.
Tagging the Image
Simply put, we want to translate our Git tag to the tag for our container. This value is available to us, oddly enough through the Build.SourceBranchName environment variable. So we can use this in our Image Build and Push steps to correctly tag and push the right image.
Admittingly, this is a bit weird but, if you remember how we triggered it does make sense. I do hope Microsoft exposes this in a cleaner way moving forward because, it is not obvious you can do this.

The last thing we want to do is make sure that we build our .NET code in Release mode, since this is code that could potentially go into Production. The easiest way to do this is to create a copy of your Dockerfile and update Debug to Release.
Also note in the Image name the -release suffix added to the Image Name. This is so we do not drop this into our Dev repo (containertest). While there is no harm in doing such, I find this is easier to know which builds are releases and prevent mistakes.
Methodology
When we create a QA release we should view this as something that MIGHT go to Production. In reality, the vast majority of Release builds will be discarded somewhere along the way, but at least one will/should make it all the way through.
Additionally, in a proper build process we NEVER want to rebuild code that has been validated by a testing process as it opens the chance that a bug slips by. Thus, when we create a Release build that is the last time that code is compiled. This is where Containers really shine vs something like ZipFile deploy as they are specifically designed with this case in mind.
Finally, by separating our Dev and Release builds we are able to have a history and allow for easy rollbacks and deployments. By having this history, we can see a timeline of how an application developed.
Releasing the Release
So, we can use the same methodology to kick off his release build as we did with the CI build, when the build changes the release is kicked off.
Go ahead and Create a new Release Pipeline, as before we want to use Azure App Service Deployment as our template. For the Artifact, select the Release Build that was created previously. The beauty here is that since that build is ONLY triggered when a version tag is added, so this release pipeline will only ever fire when that release build is successful; this makes it ideal to deploy to QA environments.
Similar with the Release Build we created earlier, we need to reference the Build.SourceBranchName in the Deployment task so we indicate what Image we are deploying with.
As a tip, when a Release run finishes you can look at its details and click Logs and see a COMPLETE dump of all variables in context. This is VERY helpful for knowing what you have access to; this was more helpful than hours of Googling for me 🙂
Also, a good way to verify that the Release worked (in addition to visiting the Url or checking the Container Settings in the Web App) you can see the actual image and tag it attempts to deploy (you will not get an fail if the image does not exist, just Service Unavailable).
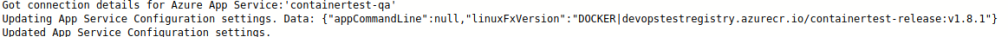
To test, create a tag anywhere in your Git commit history and push that tag to your remote. As a warning, when you do a git push it does NOT, by default, push tags. I use GitKraken so I can push tags individually. Just keep that in mind.
Also, if you are using the free tier of VSTS, it may take a second to start. You can check Queued Builds if you want to see the change was detected.
Once the build finishes, flip over to Releases and, again after some waiting, you will see the Release start. When it finishes you can check your AppService. Congrats.
Higher Environment Deployment
As we talked about before, once you build a QA release you are, effectively, creating a build that you might potentially release and, as such, rebuilding this code should absolutely be avoided. Using containers make this much easier over something like Zip.
Because we do not need to build anymore, additional actions take place only in the Release Pipeline. To close out this post, I will create a Staging Deployment where the user indicates what version they are deploying.
In Releases, choose to create a new Release Pipeline, I called mine Staging Deployment. The important thing with this pipeline is that for the Artifact Type you select Azure Container Registry (or whatever registry you are choosing to use).
Next go into the Tasks for your App Service Deployment task. Make sure we select the right Image Name (remember it is case sensitive) and use Build.BuildId for the tag. This is weird I know but, when the user creates the release they will specify a version (from the versions we have created) and it will be surface as the BuildId. Here is what mine looks like:
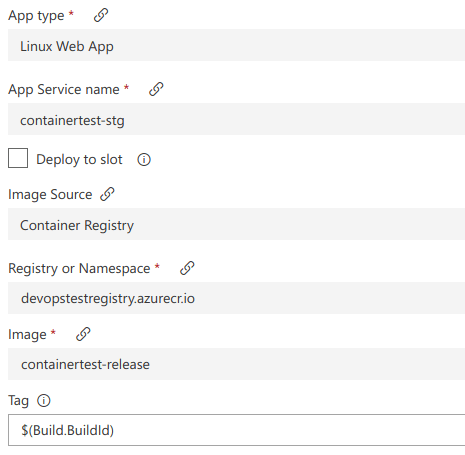
This is literally it for the configuration of the pipeline. Now, let’s invoke it.
From the Releases main landing screen select the Staging Deployment (or whatever you called it) Pipeline and from the three dots menu select + Release.
A side menu will appear prompting the user for certain details on this release, one of the, is version. When you click the dropdown a selection of available versions from the ACR will appear. Select the one you want. Here is what my screen looks like:
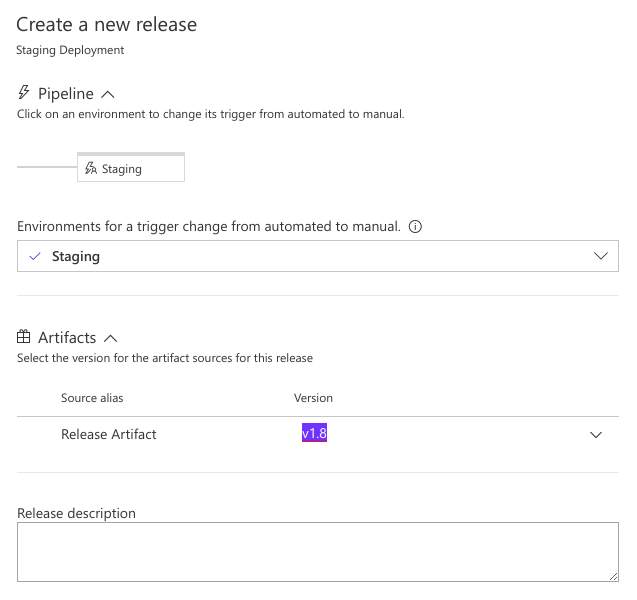
Click Create and the Pipeline will move to a Standby state, it wont actually deploy it yet, that is, correctly, a separate step.
FYI, the Refresh on these screens is a bit wonky so, make use of the manual Refresh button in the table’s upper left corner.
Here is what my screen looks like when I drill into this New Release I created.
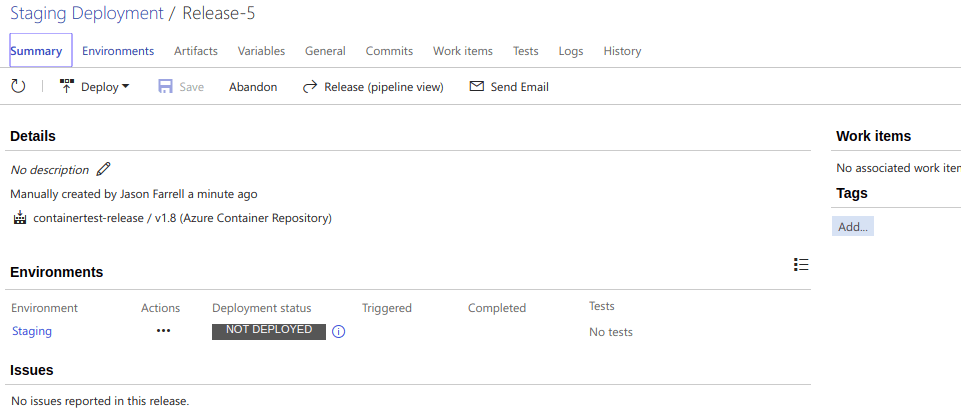
Now, we click Deploy and wait till the process ends. Mine took 3m, though I use the free tier and a local agent built on an Agent Docker Container (future post for that).
Once its complete, go verify things and you should be go.
Closing
Let me be frank, there is NO REASON to not use Containers for applications these days. Orchestration is another matter but Containers should now be the defacto standard for the vast majority of applications.
In the example above, we were able to use Git tags and tagging to identify versions and make our builds but, more than that, there is a consistency here. We have a guarantee that our applications work because they are contained and have everything they need right inside, regardless of the host OS.