Part 1 here
Continuing on with this series, we now turn our attention to how to ingest and process the data collected through the Event Hub. For real time apps, this is where we want to perform our bounded queries to generate data within a window. Remember, traditionally we naturally get bounded queries because we are querying a fixed data set. With this sort of application our data is constantly coming in and so we have to be cognizant of limiting our queries within a given window.
Creating our Stream Analytics Job
Click Add within your Resource Group and stream for Stream Analytics and look for Stream Analytics job.
For this demo, you can set Streaming Units to 1. Streaming Units is a measure of the scalability for the job, you should adjust this based on your incoming load. For more information see here.
When we look at this sort of service we concern ourselves with three aspects: Input, Query, and Output. For the job to work we will need to fulfill each of these pieces.
Configure the Input
For Input, we already have this, our Event Hub. We can click on Inputs and select Add Stream Input. From here you can select your Event Hub, you will be promoted to fill in values from the right side panel. As a tip, try to use the EventHub selection, dont try to specify the values. I have found that things wont work properly.
This provides an input into our analytics job for our next section we will configure the query.
Configure the Query
As I mentioned before, the thing to remember with this sort of process is you are dealing with unbounded data. Because of this we need to make sure the queries look at the data in a bounded context.
From the Overview for your Stream Analytics Job click the Edit Query which will drop you into the Query editor. Some important things to take note of here:
- When you created your Input you gave it a name, this serves as the table you will use as the source for your data
- The query result is automatically directed to your output. There are ways to send multiple outputs, but I wont be talking that here
So here is a sample query that I used to select the sum of shares purchased or sold on a per minute basis:
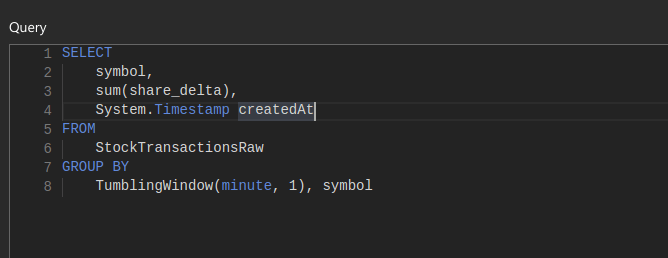
There are a couple things to point out here:
- We use System.Timestamp to produce a timestamp for the event. This will be used on the frontend if you want to graph this data over time. It also serves as a primary key (when combined with symbol) in this case
- StockTransactionsRaw is the input that we defined for this Stream Analytics job, you can call this whatever
- TumblingWindow is a feature supported within Analytics job to allow for creating a bounded query. In this case, we slide a window on a per minute basis. Here is more information on TumblingWindow – click
One big tip I can give here is using Sample Data to test. Once you have your Input stream going for a bit you can return to the Inputs list and click Sample Data for that specific input. This will generate a file you can download with the data being received through that input.
Once you have this file, you can return to the Edit Query screen and click the Test button, this will let you upload the file you downloaded and will display the query results. I found this a great way to test your query logic.
Once you have things working to your liking you need to move on to the Output.
Configure the Output
For now, we are going to use Blob Storage to handle our data. We will cover hooking this up to Cosmos in Part 3. I want to break this up a bit just so its not too much being covered in one entry and, I like 3 as a number 🙂
Click on Outputs and select Add and choose Blob Storage. Here is what my configuration looks like:
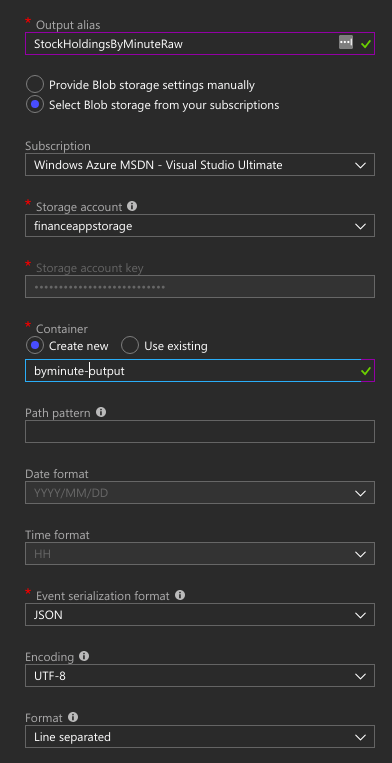
This will drop the raw data into files within your blob storage that you can read back later. Though, the real value here will be the ability to query it from something like Cosmos which we cover in the next section.
So, now you have an Event Hub that is able to ingest large amounts of data and it pumps the data into the Analytics Job which runs a query (or queries) against it and it sends the outputs, for now, to our Blob Storage.
Looking to catch you in Part 3.

3 thoughts on “Building a Real Time Data Pipeline in Azure – Part 2”