When we talk about using a “public cloud” we are most often referring to Amazon and Azure. These two represent the most mature and widely available public clouds in the world. But, Google has also been working to enhance its public cloud offerings, and given their history and technical prowess, it would not be wise to ignore them. So, given that Google gives you a nice $300 credit per month, I decided to take some time and see what I can build.
Recently, I decided to dive into GCP (Google Cloud Platform) and see what its like to build my standard microservice based Image Processor application in the platform, mostly to get a feel for what its like and its level of maturity. What I found was what I expected, good offerings but still in need of polishing when compared to AWS and Azure. Let’s walk through my example.
Setting up the function
I really do like the UI of Google Cloud, its clean and makes sense; though this could be do the lack of offerings compared to Azure and AWS which have to provide access to many more. Nevertheless, I found the UI easy to navigate.
The Project
Everything in your Google Cloud is organized into “projects”, near as I can tell. Within these projects you turn on various APIs (like Cloud functions) and define the various cloud resources the project will use; very similar to resource groups in AWS and Azure. When you access APIs, you will need to use your Project Id as a key value. Google Cloud displays your current project context in the top bar making switching between very easy.

As soon as you select the Cloud Functions options from the sidebar nav (the site is clearly built using the Material UI) you will be asked, if this is the first time, to Enable API which will allow you to actually use the feature.
Google Cloud Functions use ExpressJS under the hood. Use that to inform your Google searches.
The Function
Given they have been around only since 2016 it makes sense why this area feels behind compared to AWS and, especially, Azure. By default, Google will lay out a nice example for you but its kind of raw; I do not like the fact that when I call my trigger it will respond to ANY verb leaving it to me to write the verb isolation logic, so I hope you like that if statement to return 405s.
The inline editor is nice but, quickly becomes irrelevant once you start adding packages. I recommend using something like Visual Studio Code or Atom to do most of your code editing. As a tip, you will want to use the ZIP options when you add new files since the editor will not let you create files, at least not right now.
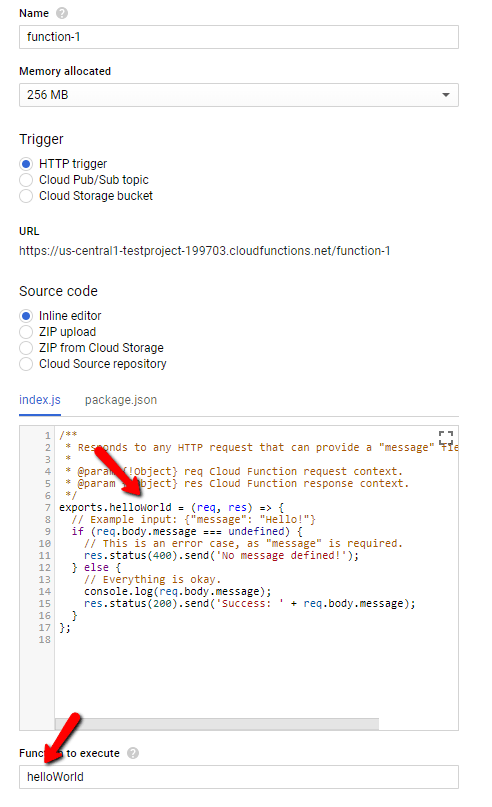
Given this, you can leverage the trigger Url (look for the Trigger tab), drop it into Postman and play with the request (only verbs supporting a body work out of the box). Also notice the above, the values indicated by the arrows must match, standard JavaScript stuff.
Meet the Emulator
Google provides a Cloud Functions emulator that you can install via an NPM package (instructions). It provides a good way to play with functions locally and easily see a result. However, this product is still very much in alpha and I ran into some problems:
- You need to deploy after any file change. While I sometimes saw my function updated in real time, it was not consistent and I chased a bug for a good while because I thought my code was updating
- Get familiar with functions logs read –limit=## this is the best way to debug functions. I couldnt get the debug command to work. Using console.log you can drop messages into the local logs.
- When you deploy you are deploying to the emulator, NOT the Cloud
- File Uploads do not seem to work. Hard as I tried, even using the exact code form the Cloud Functions tutorial (here) my file would always appear absent, even though Content-Length was correct. Not sure what is going on.
Overall, the Emulator is a nice add on, but it needs a bit more add before I can say its a valuable tool for development. I lost a few hours on my File Upload try before I did a sanity check and discovered that the file was being passed in the Cloud verison but not the emulator.
Development Flow
What I ended up doing to get this working was I would write my changes, do my NPM stuff in VSCode and then copy paste into the online Function Editor, Deploy it and run it. All the while I had my Log Viewer open and actively streaming new log entries to me. There is a process that allows use of Source Control to deploy changes, I didnt get to look at that (here). The code I am going to show below was mostly built using this copy and paste approach; nostalgically, this is what I used to do with AWS Lambda and Azure Functions before the tooling got better.
The Code
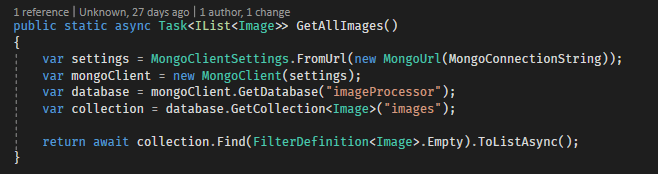
I kept the Busboy library reference, though I never got it to call its finish action, not sure why. The final version just calls my success once the save to Cloud Storage finishes. Here is our code which accepts the file being uploaded:
const Busboy = require('busboy');
exports.upload = (req, res) => {
if (req.method === 'POST') {
const busboy = new Busboy({ headers: req.headers });
// This callback will be invoked for each file uploaded.
busboy.on('file', (fieldname, file, filename, encoding, mimetype) => {
console.log('got the file');
res.sendStatus(200);
});
busboy.end(req.rawBody);
} else {
res.status(405).end();
}
}
My hope is this runs straightaway in your inline editor (I did test this). Make sure Postman is set to use form-data as its type (I always also drop a Content Type multipart/form-data into the headers as well to be safe) and you send a file up. If all goes well, in your logs you see a message got the file.
Enter Storage
Ok, so what we wrote above is pretty worthless. What we want to do is drop this into a Storage bucket for long term storage. To create storage in Google Cloud, revisit the left hand nav bar and select Storage. From the subsequent interface create a new storage bucket.
Remember the name of you bucket, you will need it in our next section.
Save to Storage
This is an area where I found a pain point. I do not like to save a file to disk and THEN upload it to storage, I want to upload the stream; its faster. With the current NodeJS Client (npm install @google-cloud/storage) you cannot do this, you MUST provide a physical path for upload to use [link]. Am hoping that gets added in future versions.
Here is the code, changed with our Storage upload call (note the save to a temporary directory preceding the storage upload).
const bucketFileName = uuid();
const tmpPath = path.join(os.tmpdir(), bucketFi
console.log(tmpPath);
file.pipe(fs.createWriteStream(tmpPath));
const storage = new Storage({
projectId
});
const bucketName = 'image-processor-images';
storage
.bucket(bucketName)
.upload(tmpPath, {
destination: bucketFileName
})
.then(() => {
console.log('write complete');
res.sendStatus(200);
})
.catch((error) => {
console.log(error);
res.sendStatus(500);
});
This code happens inside the busboy.on(‘file’,…) handler. To ensure uniqueness of the blobs I use the uuid library to generate a unique name. Finally, you can see the reference to projectId which is the Id of the project. You can get this by clicking your project in the top bar.
If you run the same call as before in Postman, it should store the uploaded file in your Storage account. One note, Max is 10MB per file. Google has a way to take larger files, but I didnt look into it yet.
Overall Thoughts
Overall, I was impressed with Google and I like what I saw. Sure it wasnt the smoothest development process, but I find it better than AWS and Azure were at the same points in development. I think the big focus needs to be on the developer experience, because ultimately that is how you get developers to want to use your platform and, ultimately, push it when they influence the choice.
But, I think Google is going to end up being a serious player just because they are Google and this sort of thing (Cloud and large scale processing) is what they are known for. So, I view this as essential but, it would still need more maturation before I would consider it in the same breath as AWS and Azure.
That hard part for Google will be getting traction. The $300 per month credit is awesome because it gives a lot of flexibility to really explore the platform and potentially recommend it. Next, I plan to check out their Database offerings.