Part 1: Building a Real Time Event Processor – Part 1
Welcome to Part 2 of this series on building a real time pipeline using Azure Services and Azure Functions. In the first part, we talked through the services we will use and laid out our goals for this project. Chief among them was to ensure we leveraged Azure Function bindings to their fullest to eliminate the need to write boilerplate connect code for various Azure services. By doing this we allow the underlying service to handle this for us.
At the end of Part 1 we had create our Timer function which was responsible for routinely running and sending data into our pipeline by way of a Service Bus Queue. Now, we will write the code to dequeue our data and send it to Azure Blob Storage and an Azure Event Hub.
Dequeue Our Data
The data we stored in the queue takes the following format:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "id": "Guid", | |
| "data": [ | |
| { "name": "string" } | |
| ] | |
| } |
Remember, when messages are stored in Service Bus they are stored as UTF8 byte arrays to reduce space. The trigger will convert this to a string or if the destination type is a complex object, it will attempt to deserialize it to that type. Here is the code for our function:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| [FunctionName("DequeueGeneratedNames")] | |
| [return: Blob("raw-names/{id}.txt", FileAccess.Write, Connection = "AzureWebJobsStorage")] | |
| public static async Task<string> Run( | |
| [ServiceBusTrigger("newnames-queue", Connection = "ServiceBusConnection")]NamesGenerationRecord msg, | |
| [EventHub("names", Connection = "EventHubSendConnection")]IAsyncCollector<string> outputEvents, | |
| ILogger log) | |
| { | |
| foreach (var nameRecord in msg.GeneratedNames) | |
| { | |
| await outputEvents.AddAsync(nameRecord.ToString()); | |
| } | |
| return msg.ToString(); | |
| } |
In my opinion, when you see code like this you are using Azure Functions to their fullest extend. Our function consists of a loop and that is it – and truthfully we could probably use some LinqFu to remove even that.
What this method does is a few things:
- First, the trigger for the Service Bus upconverts the byte array into a standard string. But because the destination type is not a primitive (NamesGenerationRecord) the trigger will attempt to deserialize the string into that object.
- Next, we define an Output binding for an Event Hub which forces the destination type of IAsyncCollector<T> to capture event string that need to be set to our Event Hub. And because it would not make sense to send only one event, it is a collection which will send asynchronously as we add additional messages
- Finally, we define the return as going to a Blob. This return will write our raw Json contents to a Blob entry with the {id} name. More on this is a second as its really neat but not well documented.
We get all of that functionality with mostly attribution. That is what I call super cool. Before we move on, let’s talk about the return of this function and how it works.
Understanding Bindings
So, what gets stored in the Service Bus is a JSON string that looks like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "id": "81d2f5b5-ca6f-464e-bfb4-b8de7a0121e8", | |
| "data": [ | |
| { "name": "Elvis Costello" }, | |
| { "name": "Bruce Willis" }, | |
| { "name": "August Meyer" } | |
| ] | |
| } |
When the ServiceBusTrigger delivers this string to the function it notes that its not delivering a string but rather an instance of NamesGenerationRecord which has this definition:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public class NamesGenerationRecord | |
| { | |
| [JsonProperty("id")] | |
| public string Id { get; set; } | |
| [JsonProperty("data")] | |
| public IList<JObject> GeneratedNames {get; set; } | |
| public override string ToString() | |
| { | |
| var data = new JObject( | |
| new JProperty("id", Id), | |
| new JProperty("data", GeneratedNames.Select(x => new JObject( | |
| new JProperty("name", x) | |
| ))) | |
| ); | |
| return data.ToString(); | |
| } | |
| } |
Crucial here is that we create a property called Id. It is this property value that will be bound to the {id} in our return template:
[return: Blob(“raw-names/{id}.txt”, FileAccess.Write, Connection = “AzureWebJobsStorage”)]
Initially, I thought this would view the string as JSON and create a JObject from it and look for an JToken with the name id but, when I tried that I received errors around the runtime being unable to find the id field to bind to. Using a custom object solved this problem.
I found this very interesting and it gives enormous possibilities. Given the way Microsoft tends to operate its likely the many of the functions support this for both Output and Return bindings.
The end result here is for each item dequeued from our Service Bus Queue we will create a blob in the raw-names container with a name of a Guid ensuring a high degree of uniqueness.
Preparing the Event Hub
Simply storing this data is not all that interesting although this is a great way to build a Data Lake that can serve well for running queries of a historical nature. The value we want is to analyze our data in real time. There are services that could handle this, with vary degrees of scalability and success:
- Azure Event Hub
- Azure Event Grid
- Azure Service Bus
- Azure Blob Storage
Some of these options may not make sense to you and that is fine. I said they COULD work for this scenario but, its unlikely using something like the change feed of an Azure Blob Storage would make a lot of sense but it could work.
Among these options, the BEST service, in my view, for our scenario is Azure Event Hub due to being cost effective and highly scalable with minimal latency. It also enforces ordering within partitions and can hold vast amounts of data for days at a time.
Further, it also hooks in well with Azure Stream Analytics Jobs which are vital to real time processing pipelines.
To setup and Event Hub, follow the instructions here: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-create
Here is a visual of what the communication between the Azure Function and Event Hub looks like – I am assuming 5 names per queue message which translates to 5 events sent to Event Hub.
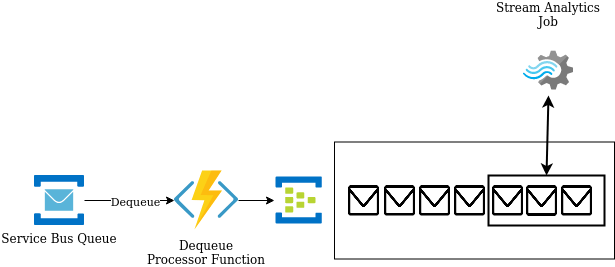
For this visualization I created a view inside the Event Hub as messages are being sent along. In this situation EACH execution of the Dequeue Processor Function will send 5 envelopes to Event Hub. These will get processed in order as they all live within the same partition.
Real Time Aggregation with Stream Analytics Job
I cannot count how many times I have come across code bases where developers have chosen to use an Azure Function or some other code based implementation to implement aggregation. While this works it is far from ideal. The Stream Analytics Jobs are the recommended approach both from the standpoint of scale and ease of use – better to write a SQL query to perform aggregation using many machines than attempt to rely on the Azure Function runtime.
Here is an example of the query I used for this exercise:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| WITH | |
| FirstLetters AS | |
| ( | |
| SELECT SUBSTRING(name, 1, 1) as letter | |
| FROM [NamesData] | |
| ), | |
| LetterCounts AS | |
| ( | |
| SELECT letter, COUNT(letter) as letterCount | |
| FROM [FirstLetters] | |
| GROUP BY letter, TumblingWindow(second, 30) | |
| ) | |
| SELECT * INTO [SaveGroupedData] FROM LetterCounts |
This query executes in three phases.
First, it reads from our Input which in this case is NamesData an alias for the Event Hub which our Azure Function was pouring data into in the previous section. This looks at each name entry and grabs the first character (base 1) from each Name in the data set. This subquery results are named FirstLetters.
Next, the subquery results are used as the source for another subquery, LetterCounts. This query takes the first data and counts how many times each letter appears in the set. Key to this query is not just the grouping logic but the TumblingWindow. Let me explain.
Remember that you are not querying against a standard database of data with these queries. Your data set is consistently moving, considerably so in high volume cases. For this reason, you MUST restrict what data your query considers using windows. Stream Analytics supports 4 of these windows:
- Tumbling
- Session
- Hopping
- Sliding
Depending on how fluid you want your data to be generated you would pick the appropriate window. They are described here: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions.
For our example, we use Tumbling which segments the event stream into a distinct windows and ensures events do not cross into other segments. In the case of the query above, we get the events broken into 30s intervals with each event belonging to one and only one segment. There are use cases for wanting events to belong to multiple segments, as is the case with Sliding Windows.
The final bit of this query select the results of LetterCounts into the Output SaveGroupdData which fronts an Azure Function to take our aggregated data to the next stage.
Up Next
In this post, we continued to lessons of Part 1 and dequeue our raw data, parsed it and sent the raw events into our Event Hub. Within the Event Hub our data is stored (temporarily for x days) and it can be read by various processes in real time. One of the best ways to perform this reading is using Azure Stream Analytics jobs which enable SQL like querying of data in the stream using windows to execute data segmentation. The result was a sequence of writes to our output Azure Function (we will discuss in Part 3) with the aggregated data results from the query.
In the next segment we will store our Aggregate results and notify connected clients who may update their UIs display our real time data.
One Note
One of the most popular outputs for Stream Analytics jobs is Power BI. This tool can take in the data and build these auto updating charts to represent data within the stream. I was not able to use Power BI for this but it is a common output for use cases like this.

4 thoughts on “Building an Real Time Event Processor – Part 2”