So, I decided recently to undertake a challenge to build an end to end real time processing pipeline using Azure Functions. They key here would be to only use Outbinding bindings, triggers, and return bindings to communicate with other Azure services. In this way, it lessens the amount of code needed and reduces overall chances for bugs.
In addition, it gives insight into potential ways of building real time data processing clients, a scenario becoming increasingly common in business. Further, they are a challenge and require intense communication and collaboration with various persons to ensure the data is partitioned and chunked appropriately. Throw in the cloud dimension where our setup needs to be cost effective as well as functional and its quite the challenge.
Let’s get started.
Understanding Bindings
One of the most useful feature in Azure Functions is bindings whereby we can encapsulate functionality that would normally necessitate boilerplate code for a simple attribute on a parameter. This allows the function to communicate with many things and the management of that communication to be handled by Azure.
Perhaps the most popular and well known binding is HttpTrigger whereby a Azure Function is triggered when a Http request is made that matches a specific pattern. This trigger outputs itself as HttpRequest instance which contains all of the information about the incoming request. Other triggers function in similar ways – I even have a post about writing a custom binding.
Regardless, when using Azure Functions you should aim to heavily use bindings as much as possible. It will save you from writing bad or incorrect service connection code.
Enough of that, let’s talk shop.
The Architecture of our Pipeline
Selection of services is critical when designing a real time pipeline, each case will be different and have different limitations. Recently, I helped a client understand the difference between Azure IoT Hubs and Event Hubs and what scenario is geared for. In that case explaining that IoT hubs allow for an enormous amount of concurrent connections (sensible given the use case) where Event Hubs allow a fair number but much less than IoT. This limitation often informs other architecture decisions you would make.
For our sample, I choose the following services:
- Azure Functions – should not come as a surprise. They are the backbone and connectors of the event pipeline. As a rule of thumb, which building an Azure Function be mindful of its responsibilities. They are not designed to be large and there are certainly better services for performing heavy amounts of processing
- Event Hub – Event Hubs are designed to handle large amounts of data and maintain order within partitions and minimal latency. It is able to send its incoming data blocks to multiple services for processing. If Capture is enabled, Event Hub can store each event it receives in an associated blob storage. The blob storage could serve as a simple Data Lake over time
- Stream Analytics Job – This service enables queries to be run over the data in Event Hub. It is commonly used to aggregate windows of data and send results to other services for storage and further processing. These windows exists because, in a real time application, the data set is never fixed.
- CosmosDb (Core) – CosmosDB is Microsoft’s global NoSQL database solution used to support various providers for global and multi-region scenarios. Due to it being NoSQL it favors the AP portion of the CAP theorem (https://en.wikipedia.org/wiki/CAP_theorem) and this is well suited to a situation where it will receive data frequently and in a controlled manner where consistency is not a major concern
- Azure SignalR Service – SignalR enables transmission of new aggregate data sets from Stream Analytics to connected users. This could power charts or graphs in real time to allow for more visibility of per minute operations
Now that we know the services here is a visual of how they are connected:
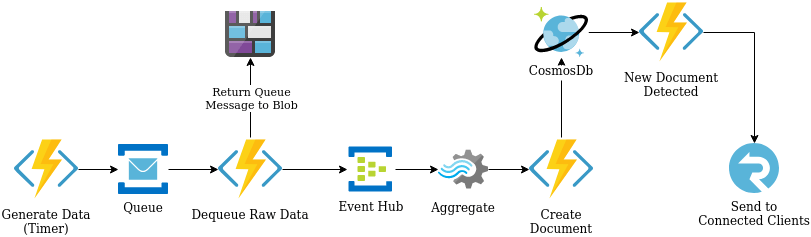
A few things of note that we take advantage of in this pipeline:
- CosmosDb supports change feeds which an Azure Function can monitor and trigger itself when a change is detected. This enables the so called streaming architecture that underpins this sort of pipeline. It lets the entire system respond when something in data changes
- At the Dequeue stage we use a combination of return and output binding to send our data to two places. Further, we use a binding to parameterize out Blob return so we can set the name of the blob created (we will explore in code later in this series). The use of Output bindings with Azure functions enables the function to initiate more than one service as an output OR, in the case of Event Hub, notify the service multiple times through the course of one iteratiom
Now that we understand our flow, let’s look at our first Azure Function – a Timer Trigger.
Phase 1: Generate our Data
Data plays a huge role in a real time processing pipeline. In my smaller example I have service which generates random Western style names. My goal is to capture these names and send them to the queue. The size of this data can vary since I may get back 4 names or 10. Here is the code for the function:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| [FunctionName("GenerateNamesTimerFunction")] | |
| [return: ServiceBus("newnames-queue", Connection = "ServiceBusConnection")] | |
| public static async Task<string> RunTrigger( | |
| [TimerTrigger("*/3 * * * * *")]TimerInfo myTimer, | |
| ILogger log | |
| ) | |
| { | |
| var names = await GetNames(); | |
| var output = (new JObject( | |
| new JProperty("id", Guid.NewGuid().ToString()), | |
| new JProperty("data", names.Select(name => new JObject( | |
| new JProperty("name", name) | |
| ))) | |
| )).ToString(); | |
| return output; | |
| } |
This code uses a ServiceBus return string – this will cause whatever string we return from this function to be added to a Service Bus queue named newnames-queue in its raw JSON form (this is why we use the Linq to Json sytle from Json.Net library). The binding will take care of encoding the string into a byte array to minimize transport and storage size while it resides in the queue.
In the attribution for this function, you can see we specify the queue name as well as the connection string (without the Entity Path) to the Service Bus. The Configuration setting ServiceBusConnection is set for the Azure Function app and the attribute will handle resolving it.
Up next
This brings us to the end of Part 1 of this series. Our next part will show how we dequeue this message in a way that maintain strong typing and send it to both blob storage and Event Hub in one fell swoop.

5 thoughts on “Building an Real Time Event Processor – Part 1”