Kubernetes is a container orchestration framework from Google that has become a highly popular and widely used tool for developer seeking to orchestrate containers. The reasons for this are centered around the continued desire by developers and project teams to fully represent all aspects of their application within their codebase, even beyond the source code itself.
At its simplest form Kubernetes is an automated resource managed platform that works to maintain a declared ideal state for a system via the use of YAML-based spec files. While the topic of Kubernetes is very deep and encompasses many aspects of architecture and infrastructure there are 5 crucial concepts for the beginner to understand.
The Five Concepts
Cluster – the term Cluster essentially refers to a set of resources being managed by Kubernetes. The cluster can span multiple datacenters and cloud providers. Effectively each Cluster has a single control plane.
Node(s) – represents the individual blocks of compute resource that the cluster is managing. Using a cluster like minikube you only get a single node whereas many production system can contain thousands of nodes.
Pod – the most basic resource within Kubernetes. Responsible for hosting one or more containers to carry out a workload. In general, you will want to aim for a single container per pod unless using something like the sidecar pattern
Deployment – at a basic level ensures a minimum number of Pods are running per a given spec. Pod count can expand beyond this level but the replica count ensures a minimum. If number drops below, additional pods are recreated to ensure ideal state is maintained
Service – clusters are, by default, deny all and require services to “punch a hole” into the cluster. In this regard, we can think of a service as a router enabling a load balanced connection to a number of pods that match its declared criteria. Often services are fronted by an Ingress (beyond this post) which enables a cleaner entrance into the cluster for microservice architectures.
Visually, these concepts related to each other like this:
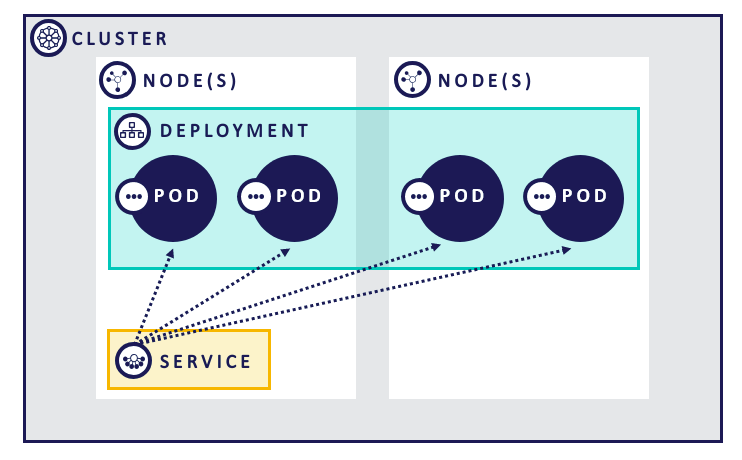
Options for Deployment
In his blog post, Kelsey Hightower of Google lays out how to setup Kubernetes yourself. Very much so, its well beyond most developers, myself included. Therefore, most of us will look towards managed options. In the cloud, all of the major players have managed Kubernetes options:
- Azure Kubernetes Service
- Google Kubernetes Engine (among other offerings)
- Elastic Kubernetes Service (AWS)
- Digital Ocean Kubernetes
Each of these options are very recent versions of Kubernetes and are already supporting customer deployments. However, one of the advantages Kubernetes comes with as a resource management platform, is the ability to also managed OnPrem resources. Due to this we have seen the rise of managed on-prem providers:
- Magnum (Open Stack)
- Metal (cubed) – https://github.com/metal3-io/metal3-docs
- Docker for Kubernetes
There is also minikube (https://kubernetes.io/docs/tasks/tools/install-minikube/) which serves as a prime setting for development and localized testing.
Deploying Our application
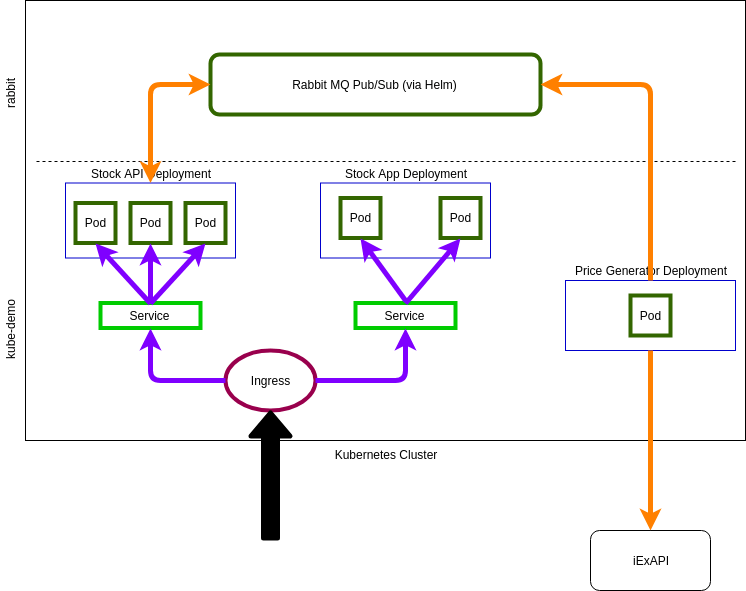
This is the application we are going to deploy, the pieces are:
- Price Generator – gets latest stock price for some stock symbols and uses a random number generator to publish price changes to RabbitMQ
- RabbitMQ – installed via Helm chart – receives price change notifications and notifies subscribers
- StockPrice API – .NET Core Web API – listens for Price Changes and sends price changes to listening clients via SignalR
- StockPrice App – ReactJS SPA application receives price changes via SignalR and updates price information in its UI
With the exception of RabbitMQ, each of these pieces are deployed as Docker containers from Docker Hub. Here is a sample Dockerfile to build the .NET pieces:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| FROM mcr.microsoft.com/dotnet/core/sdk:2.2.203 as build | |
| WORKDIR /code | |
| COPY . . | |
| RUN dotnet restore | |
| RUN dotnet publish -o output -c Release | |
| FROM mcr.microsoft.com/dotnet/core/aspnet:2.2 as runtime | |
| WORKDIR /app | |
| COPY –from=build /code/output ./ | |
| EXPOSE 80 | |
| ENTRYPOINT [ "dotnet", "StockPriceApi.dll", "–environment=Cluster" ] |
You can ignore the –environment flag – this was something I was trying for with regard to specifying environment level configuration.
Next we push the image to Docker Hub (or which ever registry we have selected) – https://cloud.docker.com/u/xximjasonxx
For reference, here is the sequence of commands I ran for building and pushing the StockPriceApi container:
docker build -t xximjasonxx/kubedemo-stockapi:v1 .
docker push xximjasonxx/kubedemo-stockapi:v1
Once the images are in a registry we can apply the appropriate spec files to Kubernetes and create the resources. Here is what the StockAPI spec file looks like:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| apiVersion: apps/v1 | |
| kind: Deployment | |
| metadata: | |
| name: stockapi-deployment | |
| namespace: kube-demo | |
| labels: | |
| app: stockapi | |
| spec: | |
| replicas: 3 | |
| selector: | |
| matchLabels: | |
| app: stockapi | |
| type: pod | |
| template: | |
| metadata: | |
| labels: | |
| app: stockapi | |
| type: pod | |
| namespace: kube-demo | |
| spec: | |
| containers: | |
| – name: stockapi-container | |
| image: xximjasonxx/kubedemo-stockapi:v2.2.1 | |
| — | |
| apiVersion: v1 | |
| kind: Service | |
| metadata: | |
| name: stockapi-service | |
| namespace: kube-demo | |
| spec: | |
| selector: | |
| app: stockapi | |
| type: pod | |
| ports: | |
| – protocol: TCP | |
| port: 80 |
What is defined here is as follows:
- Define a Deployment that indicates a minimum of three replicas be present
- Deployment is given a template for how to create Pods
- Service is defined which includes matching metadata for the Pods created by the Deployment. This means, no matter how many Pods there are, all can be addressed by the service
To apply this change we run the following command:
kubectl apply -f stockapi-spec.yaml
Advantages to using Kubernetes
The main reason orchestrators like Kubernetes exist is due the necessity with using automation to manage the large number of containers required to support higher levels of scale. However, while a valid argument, the greater advantage is the predictability, portability, and managability of applications running in Kubernetes.
One of the big reasons for the adoption of containers is the ability to put developers as close to the code and environment in production. Through this, we gain a much higher degree of confidence that our code and designs will execute as expected. Kubernetes takes this a step further and enables us to, in a sense, containerize the application as a whole.
The spec files that I shard can be run anywhere that support Kubernetes and it will run, more or less the same. This means we can now see the ENTIRE application as we need it, not just pieces of it. This is a huge boon for developers, especially those working on systems that are inherently difficult to test.
When you start to consider, in addition, tools like Ansible, Terraform, Puppet and how they can effect configuration changes to Spec files. And that clusters can span multiple enviroments (cloud provider -> on-prem, multi cloud provider, etc) there are some interesting scenarios that come about.
Source Code is available here: https://github.com/xximjasonxx/kubedemo
I will be giving this presentation at Beer City Code on June 1. It is currently submitted for consideration to Music City Code in Nashville, TN.

2 thoughts on “An Intro to Kubernetes”