The next entry in this series is something that hits very close to home for me: Serverless for APIs. Let me first start off by saying, I am not stating this as an unequivocal rule. As with anything in technology there are cases where this makes sense. And, in fact, much of my consternation could be alleviated by using Containers. Nevertheless, I still believe the following to be true:
For any non-simple API, a serverless approach is going to be more harmful and limiting, and in some cases more costly, than using a traditional server.
Background
When AWS announced Lambda back in 2014 it marked the first time a major cloud platform had added support for what would be come known as FaaS (Function as a Service). The catchphrase was serverless which, did not make a lot of sense to people since there was obviously still a server involved – but marketing people gotta market.
The concept was simple enough, using Lambda I could deploy just the code I wanted to run and pay per invocation (and the cost was insanely cheap). One of the things Lambda enabled was the ability to listen for internal events from things like S3 or DynanmoDB and create small bits of code which responded to those events. This enabled a whole new class of event driven applications as Lambda could serve as the glue between services – EventBridge came along later (a copy of Azure’s EventGrid service) and further elevated this paradigm.
One of the Events is a web request
One of the most common types of applications people write are APIs and so, Lambda ensured to include support for supporting web calls – effectively by listening for a request event coming from outside the cloud. Using serverless and S3 static web content, a company could effectively run a super sophisticated website for a fraction of the cost of traditional serving models.
This ultimately led developers to use Lambda and Azure Functions as a replacement for Elastic Beanstalk or Azure App Service. And this is where the misconception lies. While Lambda is useful to glue services together and provide for simple webhooks it is often ill-suited for complex APIs.
The rest of this will be in the context of Azure Functions but, conceptually the same problems existing with Google Cloud Functions and AWS Lambdas.
You are responding to an Event
In traditional web server applications, a request is received by the ISAPI (Internet Server Application Program Interface) where it is analyzed to determine its final destination. And this destination can be affected by code, filters, and other mechanisms.
Serverless, however, is purely event driven which means, once an event enters the system it cannot be cancelled or redirected, it must invoke its handler. Consider the following problem that was encountered with Azure Function Filters while developing KlipTok.
On KlipTok there was a need to ensure that each request contained a valid header. In traditional ASP .NET Core, we would write a simple piece of middleware to intercept the request and, if necessary, short-circuit it should it be deemed invalid. While technically possible in Azure Functions it requires a fairly robust and in-depth knowledge and customization to achieve.
In the end, we leveraged IFunctionsInvocationFilter (a preview feature) which allowed code to run ahead of the functions execution (no short-circuit allowed) and mark the request. Each function then had to check for this mark. It did allow us to reduce the code but certainly was not as clean as a traditional API framework.
The above example is one of many examples of elements which are planned and allotted for in full-fledged API frameworks (being able to plug into the ISAPI being another) but are otherwise lacking in serverless framework, Azure Functions in this case. While there does exist the ability to supplement some of these features with containerization or third party libraries, I still believe such a play detracts from the intended purpose of serverless: to be the glue in complex distributed systems.
It is not to say you never should
The old saying “never say never” certainly holds true in Software Engineering as much as anywhere. I am not trying to say you should NEVER do this, there are cases where Serverless makes sense. This is usually because the API is simple or the Serverless piece is leverage by a proxy API or represents specific routes within the API. But I have, too often, seen teams leverage serverless as if it was a replacement for Azure App Service or Elastic Beanstalk – it is not.
As with most things teams need to be aware and make informed decisions with an eye on the likely road of evolution a software product will take. While tempting, Azure Functions have a laundry list of drawbacks you need to be aware of including:
- Pricing which will vary with load taken by the server (if using Consumption style plans)
- Long initial request time as the Cloud provider must standup the infrastructure to support the serverless code – often times our methods will go to sleep
- Difficulties with organization and code reuse. This is certainly much easier in Azure than AWS but, still something teams need to consider as the size of the API grows
- Diminished support for common and expected API features. Ex: JWT authentication and authorization processing, dependency injection in filters, lack of ability to short circuit.
There are quite a few more but, you get the idea. In general, the aim for a serverless method is to be simple and short.
There are simply better options
In the end, the main point here is, while you can write APIs in Serverless often times you simply shouldnt – there are simply better options available. A great example is the wealth of features web programmers will be used to and expect when building APIs that are simply not available or not easy to implement with serverless programming. Further, as project sizes grow the ability to properly maintain and manage the codebase because more difficult with serverless than with traditional programming.
In the end, serverless main purpose should be to glue your services together, enabling you to easily build a chain like this:
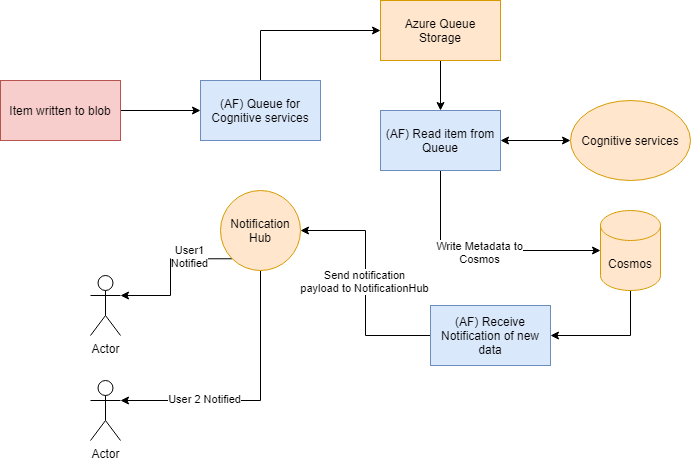
The items in blue represent the Azure Functions this sequence would require (at a minimum). The code here is fairly straightforward thanks to the use of bindings. These elements hold the flow together and support automated retry and fairly robust failure handling right out of the box.
Bindings are the key to using Serverless correctly
I BELIEVE EventBridge in AWS enables something like this but, as is typical, Microsoft has a much more thoughtout experience for developers in Azure than AWS has – especially here.
Triggers and bindings in Azure Functions | Microsoft Docs
Bindings in Azure allow Functions to connect to services like ServiceBus, EventGrid, Storage, SignalR, SendGrid, and a whole lot more. Developers can even author their own bindings. By using them, the need to write the boilerplate connect and listen code is removed so the functions can contain code which is directed at their intended purpose. One of these bindings is an input trigger called HttpTrigger, and if you have ever written a Azure Function you are familiar with it. Given what we have discussed, its existence should make more sense to you.
A function is always triggered by an event. And the one that everyone loves to listen for in the HttpTrigger that is an event to your function app which matches certain criteria defined in the HttpTrigger attribute.
So returning to the main point, everything in serverless is the result of an event so, we want to view the methods created as event handler not full fledged endpoints. While serverless CAN support an API, it lacks many of the core features which are built into API frameworks and therefore should be avoided for all but simple APIs.

I cannot say I agree with this.
For example, API Management and similar products, are specifically designed to perform these kind of request validation, request routing, throttling, security heading token validation, application of input / output policies, transformations, versioning, product licensing, monetization etc, etc, rather than attempting to do that in a standard coding approach with middleware.
And of course, API Management is available in a ‘serverless’ SKU.
It’s not ‘serverless’ that is the issue here at all, it is correctly architecting APIs – FAAS are perfectly valid for implementing an HTTP triggered end-point.
Don’t blame a drill, because you tried to use it in the same way as a hammer.
LikeLike
David,
First, thank you for leaving a reply and a dissenting one at that. I love to have these types of conversations because it is the best way to gain a new perspective.
Your comment clearly indicates I was not clear in how I expressed my point in this post. API Management, and EventGrid, Logic Apps and many others all fall into the “serverless” category and are all viable options for developing cloud applications, so to are Azure Functions and Lambda.
Where the later falls short is for complex APIs. I have had many clients attempt to build a full complex API with all of the bells and whistles in Azure Functions when it would be far better suited for Azure App Service.
To use your analogy, if my drill only supports making holes of 4″ in depth but I need to create a hole of 8″ in depth, I need a different drill.
I hope this offers some clarity. I do once again thank you for leaving a reply. Good ay to you sir
LikeLike
Thanks for aa great read
LikeLike