One of the limitations inside Kubernetes was the metrics that were supported to allow for scaling within the cluster for a deployment. The HorizontalPodAutoScaler or HPA for short, could only monitor CPU Utilization to determine if more Pods needed to be added to support a given workload. As you can imagine, in a queue based or event system, CPU usage wont tell, accurately, whether or not more pods are needed.
Note: The Kubernetes team realizing has added support for custom-metrics into the platform: https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/custom-metrics-api.md
Noticing this, Microsoft engineers began work on a project to address this, called KEDA (Kubernetes Event-Driven Autoscaling) comprised of custom resources which were capable of triggering scaling events based on external cluster criteria: queue tail length, message availability, etc. Now in 2.1 the team has added support for MANY popular external products which would dictate scaling needs in unique ways.
Here is the complete list: https://keda.sh/docs/2.1/scalers/
For this post, I wanted to walk through how to set up a configuration whereby I could use KEDA to create jobs in Kubernetes based on the tail length of an Azure Storage Queue. As is expected with a newer project, KEDA’s documentation still needs work and certain things are not entirely clear. So I view this as an opportunity to supplement the teams work. That being said, this is still very much an alpha product and, as such, I expect future iterations to not work with the steps I lay out here. But as of right now, Feb 2020, they work.
Full source code: https://github.com/jfarrell-examples/keda-queue-test
First step, Create a cluster an Azure Queue Storage
Head out to the portal and be sure to create an AKS cluster (or a Kubernetes cluster in general, doesnt matter who the provider is) and an Azure Storage account (this one you will need in Azure). Once the storage account is created, create a Queue (shown below) and saved the connection string off somewhere you can copy from later.
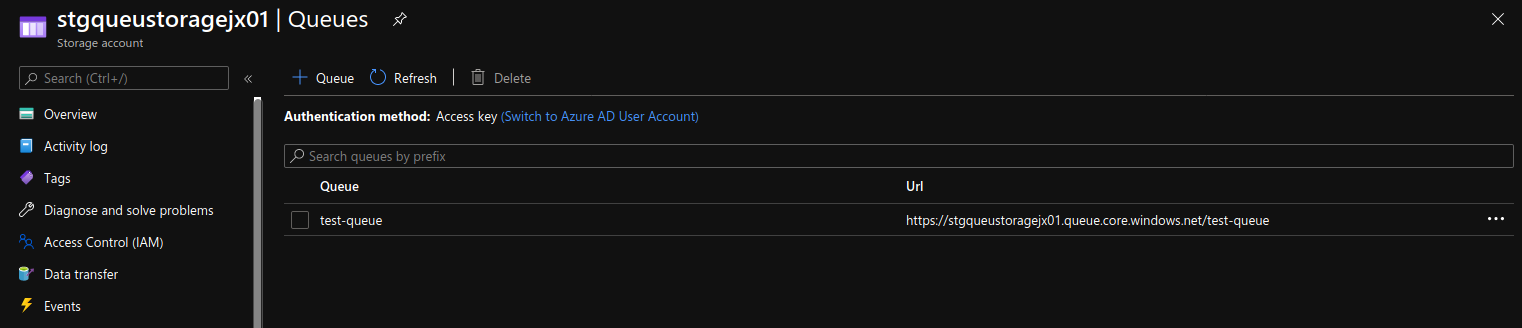
As indicated, you could use GKE (Google Kubernetes Engine) or something else if you wanted. KEDA also supports other storage and events outside of Azure but, I am using Azure Queue Storage for this demo hence why I will assume the Queue Storage is in Azure.
Now, let’s install KEDA
As with anything involving custom resources in Kubernetes, KEDA must be installed for those resources to exist. KEDA has a variety of ways it can be installed, laid out here: https://keda.sh/docs/2.1/deploy/
A quick note on this, BE CAREFUL of the version!! I am using v2.1 for this and that is important since the specification for ScaledJob changes between 2.0 and 2.1. If you read through the third approach to deployment, where you run kubectl apply against a remote file, be sure to replace the version of the file to v2.1.0. I noted with Helm at least I did NOT get v2.1 from the given charts repo.
If you run the third approach, creation of the keda namespace will happen for you, this is where the internal of KEDA will be installed and run from, your code does NOT need to go in here and I wont be doing that just to put you at ease.
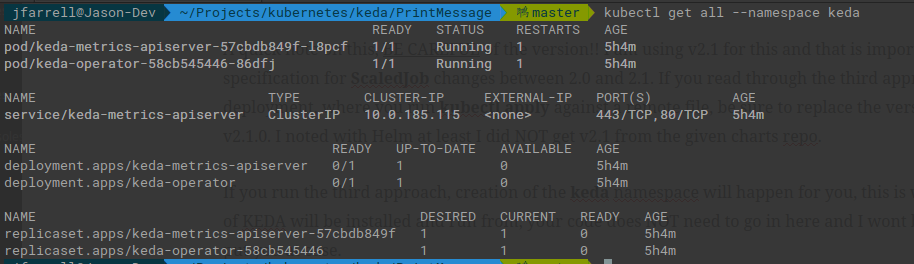
Once the installation completes I recommend running the following command to make sure everything is up and running:
kubectl get all -n keda
Note that I used the shorthand -n because I have had it happen where the –namespace doesnt copy correctly and you end up with command syntax errors. If you see something like this, KEDA is up and running:
Let’s setup the KEDA Scaler
For starters, we need a secret to hold that connection string for our Queue Storage from earlier. Here is a simple secret definition to create a secret that KEDA can use to monitor the queue tail length. REMEMBER when you provide the value to the secret it MUST be base64 encoded. I wont show my value as I do not wish to dox myself.
Linux users you can use the built-in base64 command to generate the value for the secret file. Everyone else, you can quickly Google a Base64 encoder and convert your string.
echo “your connection string” | base64
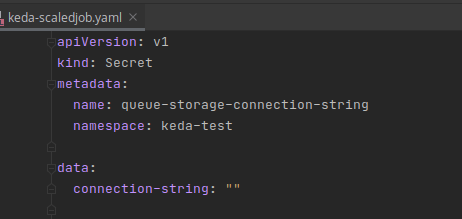
Use kubectl apply -f to create the secret. Since the namespace is provided in file, it will be placed in that namespace for you.
Next, we are going to get into KEDA specific components TriggerAuthentication and ScaledJob. These two resources will be critical to supporting our intended functionality.
First, there is the specification for TriggerAuthentication: https://keda.sh/docs/2.1/concepts/authentication/#re-use-credentials-and-delegate-auth-with-triggerauthentication
As you can see, there are a number of ways to provide authentication, we will be using secretTargetRef. The purpose is to give our trigger a way to authentication to our Queue Storage such that it can determine the various property values it needs to find out if a scaling action needs to be taken (up or down).
Building on what we did with the creation of our Secret we add the following definition and apply it via kubectl apply -f
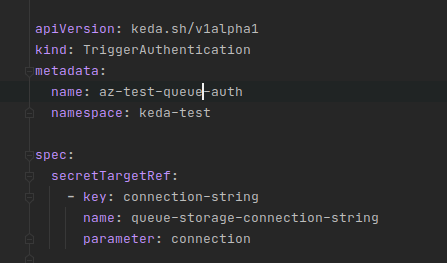
Comparing the Secret with this file you can see where things start to match up. We are simply telling the trigger it can find the connection string at the appropriate key in a certain secret. Many of the examples on the KEDA website will use podIdentity which as I have come to understand refers back to MSI. This is a better approach, albeit more complicated, than what I am showing here. We should always avoid storing sensitive information in our cluster (like connection strings) due to the less than stellar security around Secrets in general – base64 is not in anyway secure.
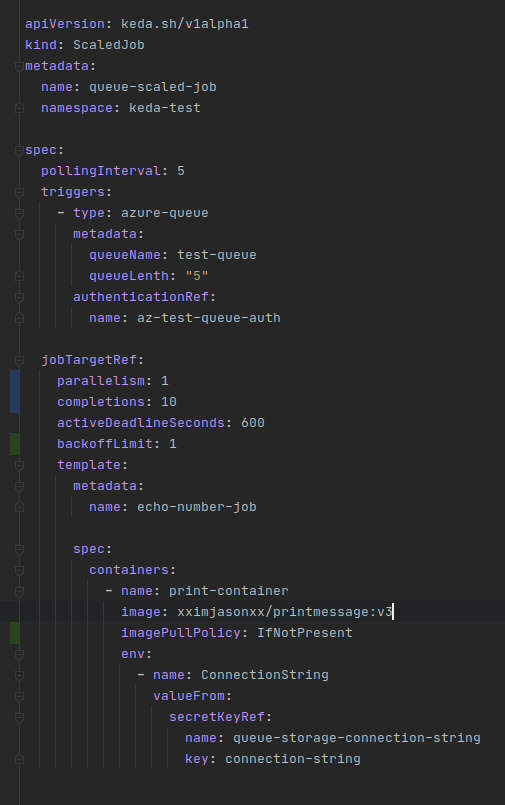
The final piece is the creation of the ScaledJob. KEDA mostly focuses around scaling deployments, which makes a lot of sense but, it can also serve to scale up Kubernetes Jobs as needed to fulfill deferred processing. Effectively, KEDA creates a psuedo deployment around the job and scales the number up as needed based on the scaling strategy specified.
This looks like quite a bit but, when you break it down it has a very straightforward purpose and a structure that is consistent with other Kubernetes objects. Let’s break it down in four parts:
The first part is identification, what we are naming the ScaledJob and where it is going to be stored within the cluster. Notice the apiVersion value keda.sh/v1alpha1 this is a clear indication of the Spec being in ALPHA meaning, I fully expect this to change.
The second part is the details for the actual ScaledJob, that is things which are specific to this instance of the resource. Here we tell the resource to check the length of our queue every 5 seconds and that it should trigger based on an azure-queue with authentication stored in our trigger auth that we defined previously.
The third and fourth part are actually all relating to the same thing which is the configuration of the created Kubernetes Job instances that will perform the work – I broke this apart based on my own personal style when constructing YAML files for Kubernetes. To keep things simple we are not going to have the job leverage parallelism, so we leave this at 1, which is also the default.
The last section lays out the template for the Pods that will carry out the work. You notice the custom image xximjasonxx/printmessage which will grab the message from the queue and print out its contents. We are also reusing the Secret here to provide the container with the connection string of the Queue so it can take items off.
All of this is available for reference in the GitHub repo I linked above.
Let’s test it
In the provided source code, I included a command line program that can send messages to our queue in the form of random numbers – SendMessage. To run this, open a Command Line window up to the directory holding the .csproj file and run the following command:
dotnet run “<connection string>” 150
The above command will send 100 messages to the queue – I should note that the queue name in the container is HARD CODED as test-queue. Feel free to download the code and make the appropriate change for your own queue name if need be – you will need to do it for both Print and Send message programs.
After running the above command you can run the following kubectl command to see the results of your experiment. Should look something like this:
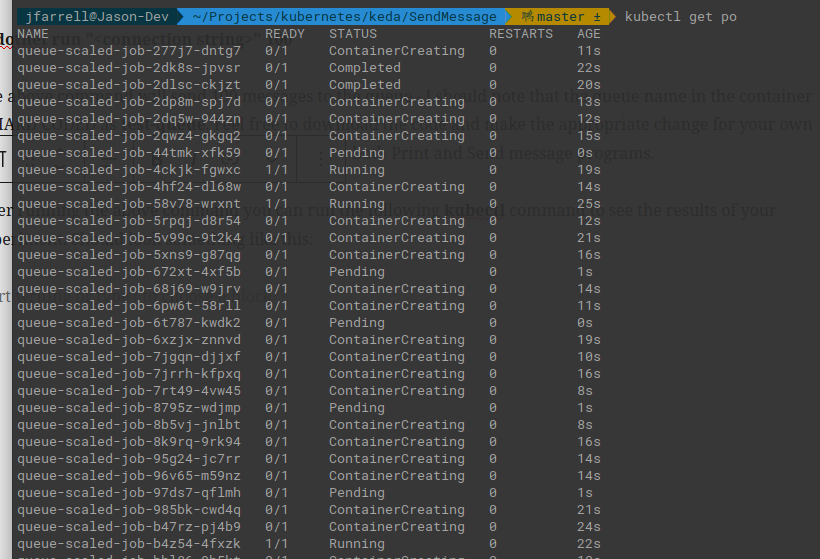
This shows that it is working and, in fact, we can do a kubectl logs on one of the pods and we can see the output message sent to the queue. Or so it appears, let’s take a closer look.
Execute the following command to COUNT how many pods were actually created:
kubectl get po | wc -l
Remember to subtract one as the wc program will also count the header line. If you get similar to what I got it will be around 300. But that does not make any sense, we only sent 150 items to our queue. The answer is, the way printmessage:v3 is written, it contains logic to print that no data was found as the queue becomes empty. While valid, with the 10 completion rule being enforced this will spin up unnecessary pods. Let’s change the image used for the job to a special image: printmessage:v3-error. This image will throw an uncaught exception when the queue is empty. The updated definition for ScaledJob is below:
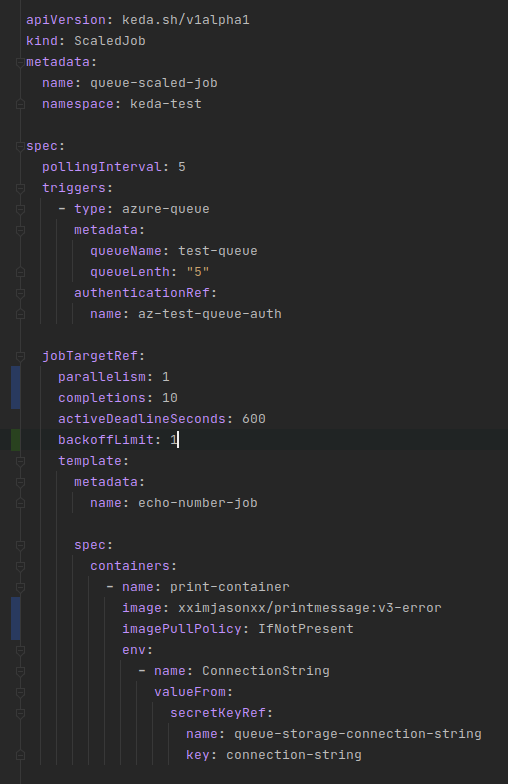
Before running things again I recommend executing these two commands, they assume the ONLY thing in the current space are jobs and pods related to KEDA. If you are sharing the namespace with other resources you will have to modify these commands.
kubectl delete po –all
kubectl delete job –all
Make sure to run kubectl apply to get the updated ScaledJob definition into your cluster. Run the SendMessage program again. This is what I got:
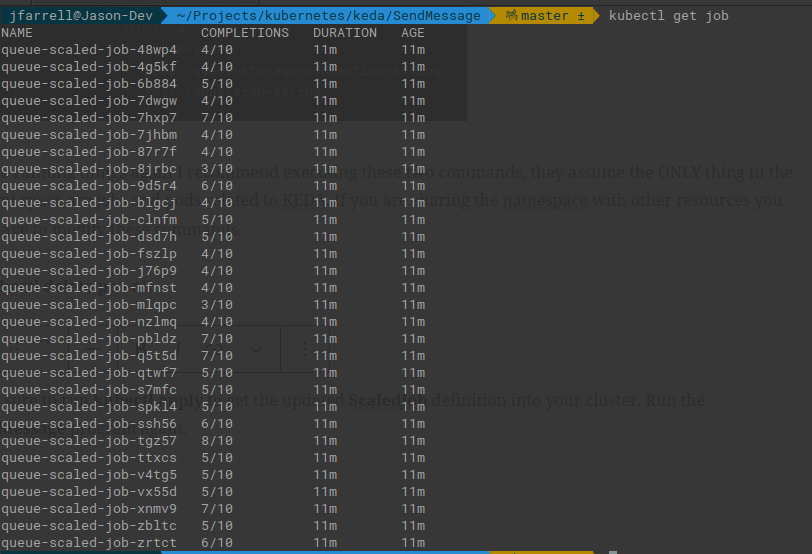
Notice how, even though we specified the job needs to complete 10 times, none of these did. Your results are likely going to vary depending on when items were pulled from the queue. But as the queue gets shorter more jobs will start to fail as the Pods attempt to grab data that does not exist.
The other thing to notice is that the Pods, if they fail, will self terminate. So, if I run my wc -l check again on the Pods I get a number that makes more sense:
kubectl get po | wc -l
Result should be 151 which, subtracting the header row gives us the 150 items we sent to the queue
Why is this happening?
The key value for controlling this behavior is the backoffLimit specified as part of the job spec. It tells a job how many times it should try to restart failing pods under its control. I have set it to 1 which effectively means it will not retry and only accept one failure.
The reason this is so important is control over resources that are scaling to match processing workloads is crucial from the standpoint of maintaining healthy resource consumption. We do not want our pods to go crazy and overwhelm the system and starve other processes.
